搜索到
55
篇与
的结果
-
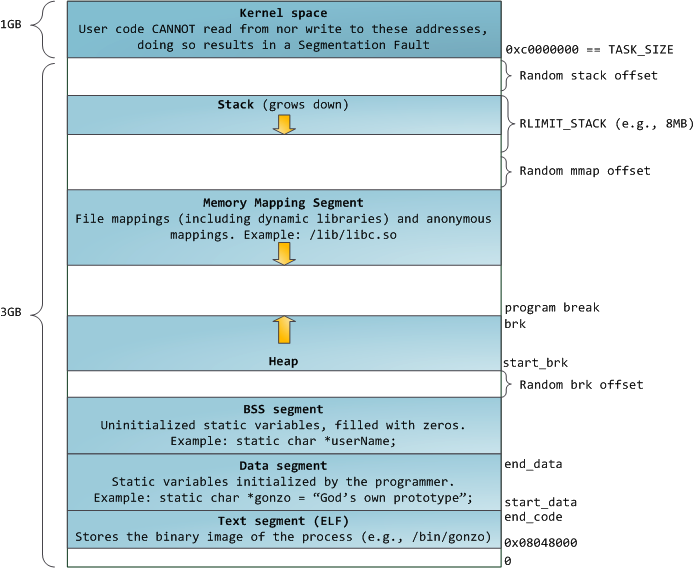
 C程序内存空间 内存空间布局原理主要解决了我的这些疑问:内存空间中分哪些大类堆内存和栈内存地址谁大多个有前后关系栈变量或者堆内存地址大小关系malloc是如何分配内存的内存池的来由内存越界写为什么往往难以定位,如何防范。内存空间的组成部分正文段(Text Segment)。 CPU执行的指令数据段(DATA Segment)。这是指的是初始化数据段。比如明确赋值的全局变量。比如int maxcount = 99非初始化数据段(BSS Segment)。也称为BSS(block started by symbol)段。在程序开始执行前,内核将此段中的数据初始化为0或空指针。比如long sum[100]栈区。自动变量和函数调用时所需保存的信息,比如函数返回地址以及调用者环境信息、临时变量。这也是递归实现业务时需要考虑的代价。递归函数每次调用自身时,都会产生一个新的栈帧。一些脚本语言实现尾调用来优化这个情况。堆区。动态分配的内存。典型x86处理器Linux内存布局(存储器安排)从上到下,分别是高地址到低地址。Kernel space. 内核使用空间,有命令行参数和环境变量等。他的地址最大,大于0xC0000000栈区。栈底则在0xC0000000开始。栈分配从高地址向低地址方向增长。注意这和一个栈区数组地址加法来实现向前并不矛盾。栈变量指向的地址其实是这次分配段的末尾地址,于是地址的加法是没有问题的。一般一个栈帧大小是2MB。内存映射区。主要动态库文件和其他文件或者匿名内存映射使用空间。堆区。malloc、free是C标准的内存申请释放接口。在Linux下还是通过sbrk/mmap系统调用来实现的。注意malloc返回的指针一定是适当对齐的,使其可以用于任何数据对象。#include <stdio.h> #include <stdlib.h>// malloc是返回void*的,包含此文件可以避免强制类型转换 int main(int argc, char **argv) { int a, b; int *c = malloc(sizeof(int)); int *d = malloc(sizeof(int)); printf("%p\n%p\n%p\n%p\n", &a, &b, c, d); free(c); free(d); return 0; }因为手头没有x86机器,即使是x64其地址布局也相似,以下是输出:[anker@ms ~]$ gcc -o test test.c [anker@ms ~]$ ./test 0x7ffd3f14b80c 0x7ffd3f14b808 0x1a172a0 0x1a172c0可以留意到栈地址是减少方向。这里又可以联系到C语言参数入栈是从右往左。即书写在前面的参数越接近栈顶,也就是书写在前面的参数内存地址越低。所以32位下C语言处理变参va_arg就是指针地址加4.堆地址是增大的方向。同时我们也留意到再次malloc返回的地址差异大于两个int长度,这是因为分配的空间比要求的稍大一些。进一步的原因是,每次申请需要额外的空间来记录管理信息(分配块的长度,指向下一个分配块的指针等等)。也正是这个块管理记录所以越界写或者重复free,除了会修改另外一个块的程序内容,还可能严重的修改了其他块的管理信息。这种错误不会很快的暴露出来,导致了内存越界难以定位。目前在VS的调试模式下是有自动检测的,但Linux环境通过设置环境变量,支持附加调试功能。同时栈地址比堆地址大。虽然sbrk可以扩充或缩小进程的堆空间,但是大多数malloc/free的实现都是不实时减小进程的存储空间,原因有:释放的空间可供以后再分配,通常他们保持在malloc池中而不返回给内核。如果频繁的申请和释放,每次都调用sbrk或者mmap都增加了系统调用次数,从而影响性能。sbrk在高地址释放但中间有较低地址没有free时也无法收缩,这也是内存碎片产生原因。因为glibc等的内部自己实现了池式结构,小于某个阈值(默认128KB)时使用brk/sbrk实现内存分配。大于这个阈值则使用mmap申请匿名空间。mmap方式可以整段释放不容易有内存碎片。另外malloc/free在多线程下,需要进行锁操作。于是有了更高效tcmalloc和jemalloc实现。 tcmalloc是分线程和进程级别缓存的。使用glibc内存池可能会存在内存回收不及时,碎片过多问题,表面看起来和内存泄漏一样只增不减。
C程序内存空间 内存空间布局原理主要解决了我的这些疑问:内存空间中分哪些大类堆内存和栈内存地址谁大多个有前后关系栈变量或者堆内存地址大小关系malloc是如何分配内存的内存池的来由内存越界写为什么往往难以定位,如何防范。内存空间的组成部分正文段(Text Segment)。 CPU执行的指令数据段(DATA Segment)。这是指的是初始化数据段。比如明确赋值的全局变量。比如int maxcount = 99非初始化数据段(BSS Segment)。也称为BSS(block started by symbol)段。在程序开始执行前,内核将此段中的数据初始化为0或空指针。比如long sum[100]栈区。自动变量和函数调用时所需保存的信息,比如函数返回地址以及调用者环境信息、临时变量。这也是递归实现业务时需要考虑的代价。递归函数每次调用自身时,都会产生一个新的栈帧。一些脚本语言实现尾调用来优化这个情况。堆区。动态分配的内存。典型x86处理器Linux内存布局(存储器安排)从上到下,分别是高地址到低地址。Kernel space. 内核使用空间,有命令行参数和环境变量等。他的地址最大,大于0xC0000000栈区。栈底则在0xC0000000开始。栈分配从高地址向低地址方向增长。注意这和一个栈区数组地址加法来实现向前并不矛盾。栈变量指向的地址其实是这次分配段的末尾地址,于是地址的加法是没有问题的。一般一个栈帧大小是2MB。内存映射区。主要动态库文件和其他文件或者匿名内存映射使用空间。堆区。malloc、free是C标准的内存申请释放接口。在Linux下还是通过sbrk/mmap系统调用来实现的。注意malloc返回的指针一定是适当对齐的,使其可以用于任何数据对象。#include <stdio.h> #include <stdlib.h>// malloc是返回void*的,包含此文件可以避免强制类型转换 int main(int argc, char **argv) { int a, b; int *c = malloc(sizeof(int)); int *d = malloc(sizeof(int)); printf("%p\n%p\n%p\n%p\n", &a, &b, c, d); free(c); free(d); return 0; }因为手头没有x86机器,即使是x64其地址布局也相似,以下是输出:[anker@ms ~]$ gcc -o test test.c [anker@ms ~]$ ./test 0x7ffd3f14b80c 0x7ffd3f14b808 0x1a172a0 0x1a172c0可以留意到栈地址是减少方向。这里又可以联系到C语言参数入栈是从右往左。即书写在前面的参数越接近栈顶,也就是书写在前面的参数内存地址越低。所以32位下C语言处理变参va_arg就是指针地址加4.堆地址是增大的方向。同时我们也留意到再次malloc返回的地址差异大于两个int长度,这是因为分配的空间比要求的稍大一些。进一步的原因是,每次申请需要额外的空间来记录管理信息(分配块的长度,指向下一个分配块的指针等等)。也正是这个块管理记录所以越界写或者重复free,除了会修改另外一个块的程序内容,还可能严重的修改了其他块的管理信息。这种错误不会很快的暴露出来,导致了内存越界难以定位。目前在VS的调试模式下是有自动检测的,但Linux环境通过设置环境变量,支持附加调试功能。同时栈地址比堆地址大。虽然sbrk可以扩充或缩小进程的堆空间,但是大多数malloc/free的实现都是不实时减小进程的存储空间,原因有:释放的空间可供以后再分配,通常他们保持在malloc池中而不返回给内核。如果频繁的申请和释放,每次都调用sbrk或者mmap都增加了系统调用次数,从而影响性能。sbrk在高地址释放但中间有较低地址没有free时也无法收缩,这也是内存碎片产生原因。因为glibc等的内部自己实现了池式结构,小于某个阈值(默认128KB)时使用brk/sbrk实现内存分配。大于这个阈值则使用mmap申请匿名空间。mmap方式可以整段释放不容易有内存碎片。另外malloc/free在多线程下,需要进行锁操作。于是有了更高效tcmalloc和jemalloc实现。 tcmalloc是分线程和进程级别缓存的。使用glibc内存池可能会存在内存回收不及时,碎片过多问题,表面看起来和内存泄漏一样只增不减。 -
为什么系统调用会消耗较多资源【转载】 这篇文章非常直白科普说明了系统调用过程,主要可以解决系统调用背后疑惑,通过经典的Hello World开始,讲述软件中断、SYSCALL/SYSENTER 等汇编指令、vDSO三方方式实现系统调用及其性能差异。非常推荐阅读。转自:为什么系统调用会消耗较多资源另外推荐相关:Linux 系统调用权威指南英文版本地址:https://blog.packagecloud.io/eng/2016/04/05/the-definitive-guide-to-linux-system-calls/系统调用是计算机程序在执行的过程中向操作系统内核申请服务的方法,这可能包含硬件相关的服务、新进程的创建和执行以及进程调度,对操作系统稍微有一些了解的人都知道 — 系统调用为用户程序提供了操作系统的接口[1]图 1 - 操作系统接口C 语言的著名的 glibc 封装了操作系统提供的系统调用并提供了定义良好的接口[2],工程师可以直接使用器中封装好的函数开发上层的应用程序,其他编程语言的标准库也会封装系统调用,它们对外提供语言原生的接口,内部使用汇编语言触发系统调用。我们在使用标准库时需要经常与系统调用打交道,只是很多时候我们不知道标准库背后的实现,以常见的 Hello World 程序为例,这么简单的几行函数在真正运行时会执行几十次系统调用:#include <stdio.h> int main() { printf("Hello, World!"); return 0; } $ gcc hello.c -o hello $ strace ./hello execve("./hello", ["./hello"], 0x7ffd64dd8090 /* 23 vars */) = 0 brk(NULL) = 0x557b449db000 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=26133, ...}) = 0 mmap(NULL, 26133, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f645455a000 close(3) = 0 ... munmap(0x7f645455a000, 26133) = 0 fstat(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 0), ...}) = 0 brk(NULL) = 0x557b449db000 brk(0x557b449fc000) = 0x557b449fc000 write(1, "Hello, World!", 13Hello, World!) = 13 exit_group(0) = ? +++ exited with 0 +++strace 是 Linux 中用于监控和篡改进程与内核之间操作的工具,上述命令会打印出 hello 执行过程中触发系统调用、参数以及返回值等信息。执行 Hello World 程序时触发的多数系统调用都是程序启动触发的,只有 munmap 后的系统调用才是 printf 函数触发的,作为应用程序我们能做的事情非常有限,很多功能都需要依赖操作系统提供的服务。多数编程语言的函数调用只需要分配新的栈空间、向寄存器写入参数并执行 CALL 汇编指令跳转到目标地址执行函数,在函数返回时通过栈或者寄存器返回参数[3]。与函数调用相比,系统调用会消耗更多的资源,如下图所示,使用 SYSCALL 指定执行系统调用消耗的时间是 C 函数调用的几十倍[4]:图 2 - 系统调用与函数调用耗时比较上图中的 vDSO 全称是虚拟动态链接对象(Virtual Dynamically Shared Object、vDSO),它可以减少系统调用的消耗的时间,我们会在后面详细分析它的实现原理。getpid(2) 是一个相对比较快的系统调用,该系统调用不包含任何参数,只会切换到内核态、读取变量并返回 PID,我们可以将它的执行时间当做系统调用的基准测试;除了 getpid(2) 之外,使用 close(999) 系统调用关闭不存在的文件描述符会消耗更少的资源5,与 getpid(2) 相比大概会少 20 个 CPU 周期[6],当然想要实现用于测试额外开销的系统调用,使用自定义的空函数应该是最完美的选择,感兴趣的读者可以自行尝试一下。图 3 - 系统调用的三种方法从上面的系统调用与函数调用的基准测试中,我们可以发现不使用 vSDO 加速的系统调用需要的时间是普通函数调用的几十倍,为什么系统调用会带来这么大的额外开销,它在内部到底执行了哪些工作呢,本文将介绍 Linux 执行系统调用的三种方法:使用软件中断(Software interrupt)触发系统调用;使用 SYSCALL / SYSENTER 等汇编指令触发系统调用;使用虚拟动态共享对象(virtual dynamic shared object、vDSO)执行系统调用;软件中断中断是向处理器发送的输入信号,它能够表示某个时间需要操作系统立刻处理,如果操作系统接收了中断,那么处理器会暂停当前的任务、存储上下文状态、并执行中断处理器处理发生的事件,在中断处理器结束后,当前处理器会恢复上下文继续完成之前的工作[7]。图 4 - 硬件中断和软件中断根据事件发出者的不同,我们可以将中断分成硬件和软件中断两种,硬件中断是由处理器外部的设备触发的电子信号;而软件中断是由处理器在执行特定指令时触发的,某些特殊的指令也可以故意触发软件中断[8]。在 32 位的 x86 的系统上,我们可以使用 INT 指令来触发软件中断,早期的 Linux 会使用 INT 0x80 触发软件中断、注册特定的中断处理器 entry_INT80_32 来处理系统调用,我们来了解一下使用软件中断执行系统调用的具体过程[9]:1.应用程序通过调用 C 语言库中的函数发起系统调用;2.C 语言函数通过栈收到调用方传入的参数并将系统调用需要的参数拷贝到寄存器;3.Linux 中的每一个系统调用都有特定的序号,函数会将系统调用的编号拷贝到 eax 寄存器;4.函数执行 INT 0x80 指令,处理器会从用户态切换到内核态并执行预先定义好的处理器;5.执行中断处理器 entry_INT80_32 处理系统调用;执行 SAVE_ALL 将寄存器的值存储到内核栈上并调用 do_int80_syscall_32;调用 do_syscall_32_irqs_on 检查系统调用的序号是否合法;在系统调用表 ia32_sys_call_table 中查找对应的系统调用实现并传入寄存器的值;系统调用在执行期间会检查参数的合法性、在用户态内存和内核态内存之间传输数据,系统调用的结果会被存储到 eax 寄存器中;从内核栈中恢复寄存器的值并将返回值放到栈上;系统调用会返回 C 函数,包装函数会将结果返回给应用程序;6.如果系统调用服务在执行过程中出现了错误,C 语言函数会将错误存储在全局变量 errno 中并根据系统调用的结果返回一个用整数 int 表示的状态;图 5 - 系统调用的执行步骤从上述系统调用的执行过程中,我们可以看到基于软件中断的系统调用是一个比较复杂的流程,应用程序通过软件中断陷入内核态并在内核态查询并执行系统调用表注册的函数,整个过程不仅需要存储寄存器中的数据、从用户态切换至内核态,还需要完成验证参数的合法性,与函数调用的过程相比确实会带来很多的额外开销[10]。实际上,使用 INT 0x80 来触发系统调用早就是过去时了,大多数的程序都会尽量避免这种触发方式。然而这一规则也不是通用的,因为 Go 语言团队在做基准测试时发现 INT 0x80 触发系统调用在部分操作系统上与其他方式有着几乎相同的性能11,所以在 Android/386 和 Linux/386 等架构上仍然会使用中断来执行系统调用[12]汇编指令因为使用软件中断实现的系统调用在 Pentium 4 的处理器上表现非常差13。Linux 为了解决这个问题,在较新的版本使用了新的汇编指令 SYSENTER / SYSCALL,它们是 Intel 和 AMD 上用于实现快速系统调用的指令,我们会在 32 位的操作系统上使用 SYSENTER / SYSEXIT,在 64 位的操作系统上使用 SYSCALL / SYSRET:图 6 - 快速系统调用指令上述的几个汇编指令是低延迟的系统调用和返回指令,它们会认为操作系统实现了线性内存模型(Linear-memory Model),极大地简化了操作系统系统调用和返回的过程,其中包括不必要的检查、预加载参数等,与软件中断驱动的系统调用相比,使用快速系统调用指令可以减少 25% 的时钟周期[13]。线性内存模型是一种内存寻址的常见范式,在这种模式中,线性内存与应用程序存储在单一连续的空间地址中,CPU 可以不借助内存碎片或者分页技术使用地址直接访问可用的内存地址。在 64 位的操作系统上,我们会使用 SYSCALL / SYSRET 进入和退出系统调用,该指令会在操作系统最高权限等级中执行。内核在初始化时会调用 syscall_init 函数将 entry_SYSCALL_64 存入 MSR 寄存器(Model Specific Register、MSR)中,MSR 寄存器是 x86 指令集中用于调试、追踪以及性能监控的控制寄存器14:void syscall_init(void) { wrmsr(MSR_STAR, 0, (__USER32_CS << 16) | __KERNEL_CS); wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64); ... }当内核收到了用户程序触发的系统调用时,它会在 MSR 寄存器中读取需要执行的函数并按照 x86-64 的调用惯例在寄存器中读取系统调用的编号以及参数,你能在 entry_SYSCALL_64 函数的注释中找到相关的调用惯例。汇编函数 entry_SYSCALL_64 会在执行的过程中调用 do_syscall_64,它的实现与上一节中的 do_int80_syscall_32 有些相似,它们都会在系统调用表中查找函数并传入寄存器中的参数。与 INT 0x80 通过触发软件中断实现系统调用不同,SYSENTER 和 SYSCALL 是专门为系统调用设计的汇编指令,它们不需要在中断描述表(Interrupt Descriptor Table、IDT)中查找系统调用对应的执行过程,也不需要保存堆栈和返回地址等信息,所以能够减少所需要的额外开销。vDSO虚拟动态共享对象(virtual dynamic shared object、vDSO)是 Linux 内核对用户空间暴露内核空间部分函数的一种机制15,简单来说,我们将 Linux 内核中不涉及安全的系统调用直接映射到用户空间,这样用户空间中的应用程序在调用这些函数时就不需要切换到内核态以减少性能上的损失。vDSO 使用了标准的链接和加载技术,作为一个动态链接库,它由 Linux 内核提供并映射到每一个正在执行的进程中,我们可以使用如下所示的命令查看该动态链接库在进程中的位置:$ ldd /bin/cat linux-vdso.so.1 (0x00007fff2709c000) ... $ cat /proc/self/maps ... 7f28953ce000-7f28953cf000 r--p 00027000 fc:01 2079 /lib/x86_64-linux-gnu/ld-2.27.so 7f28953cf000-7f28953d0000 rw-p 00028000 fc:01 2079 /lib/x86_64-linux-gnu/ld-2.27.so 7f28953d0000-7f28953d1000 rw-p 00000000 00:00 0 7ffe8ca4d000-7ffe8ca6e000 rw-p 00000000 00:00 0 [stack] 7ffe8ca8d000-7ffe8ca90000 r--p 00000000 00:00 0 [vvar] 7ffe8ca90000-7ffe8ca92000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]因为 vDSO 是由操作系统直接提供的,所以它并不存在对应的文件,在程序执行的过程中我们也能在虚拟内存中看到它加载的位置。vDSO 可以为用户程序提供虚拟的系统调用,它会使用内核提供的数据在用户态模拟系统调用:图 7 - 内核和用户控件的初始化系统调用 gettimeofday 是一个非常好的例子,如上图所示,使用 vDSO 的系统调用 gettimeofday 会按照如下所示的步骤进行初始化16:1.内核中的 ELF 加载器会负责映射 vDSO 的内存页并设置辅助向量(Auxiliary Vector)中 AT_SYSINFO_EHDR,该标签存储了 vDSO 的基地址;2.动态链接器会查询辅助向量中 AT_SYSINFO_EHDR,如果设置了该标签会链接 vDSO;3.libc 在初始化时会在 vDSO 中查找 __vdso_gettimeofday 符号并将符号链接到全局的函数指针上;除了 gettimeofday 之外,多数架构上的 vDSO 还包含 clock_gettime、clock_getres 和 rt_sigreturn 等三个系统调用,这些系统调用完成功能相对来说比较简单,也不会带来安全上的问题,所以将它们映射到用户空间可以明显地提高系统调用的性能,就像我们在图二中看到的,使用 vDSO 可以将上述几个系统调用的时间提高几十倍。总结当我们在编写应用程序时,系统调用并不是一个离我们很远的概念,一个简单的 Hello World 会在执行时触发几十次系统调用,而在线上出现性能问题时,可能也需要我们与系统调用打交道。虽然程序中的系统调用非常频繁,但是与普通的函数调用相比,它会带来明显地额外开销:使用软件中断触发的系统调用需要保存堆栈和返回地址等信息,还要在中断描述表中查找系统调用的响应函数,虽然多数的操作系统不会使用 INT 0x80 触发系统调用,但是在一些特殊场景下,我们仍然需要利用这一古老的技术;使用汇编指令 SYSCALL / SYSENTER 执行系统调用是今天最常见的方法,作为专门为系统调用打造的指令,它们可以省去一些不必要的步骤,降低系统调用的开销;使用 vSDO 执行系统调用是操作系统为我们提供的最快路径,该方式可以将系统调用的开销与函数调用拉平,不过因为将内核态的系统调用映射到『用户态』确实存在安全风险,所以操作系统也仅会放开有限的系统调用;应用程序能够完成的工作相当有限,我们需要使用操作系统提供的服务才能编写功能丰富的用户程序。系统调用作为操作系统提供的接口,它与底层的硬件关系十分紧密,因为硬件的种类繁杂,所以不同架构要使用不同的指令,随着内核的快速演进,想要找到准确的资料也非常困难,不过了解不同系统调用的实现原理对我们认识操作系统也有很大的帮助。到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:vDSO 提供的系统调用 rt_sigreturn 有哪些作用?vDSO 提供的四种系统调用中三种都与获取时间有关,为什么它可以在用户态提供 rt_sigreturn,不存在安全风险么?Fastest Linux system call https://stackoverflow.com/a/48913894Wikipedia: Interrupt https://en.wikipedia.org/wiki/InterruptHardware & Software interrupts https://en.wikipedia.org/wiki/Interrupt#Hardware_interruptsMichael Kerrisk. 2010. The Linux Programming Interface: A Linux and UNIX System Programming Handbook (1st. ed.). Chapter 3. P44. No Starch Press, USA.“int 0x80” system call path performance implications. P82. https://francescoquaglia.github.io/TEACHING/PMMC/SLIDES/kernel-programming-basics.pdfruntime, syscall: use int $0x80 to invoke syscalls on android/386 https://go-review.googlesource.com/c/go/+/16996/runtime, syscall: switch linux/386 to use int 0x80 https://go-review.googlesource.com/c/go/+/19833/Intel P6 vs P7 system call performance https://lkml.org/lkml/2002/12/9/13Wikipedia: Model-specific register https://en.wikipedia.org/wiki/Model-specific_registerWikipedia: vDSO https://en.wikipedia.org/wiki/VDSOKernel and userspace setup https://vvl.me/pdf/LPC_vDSO.pdf
-
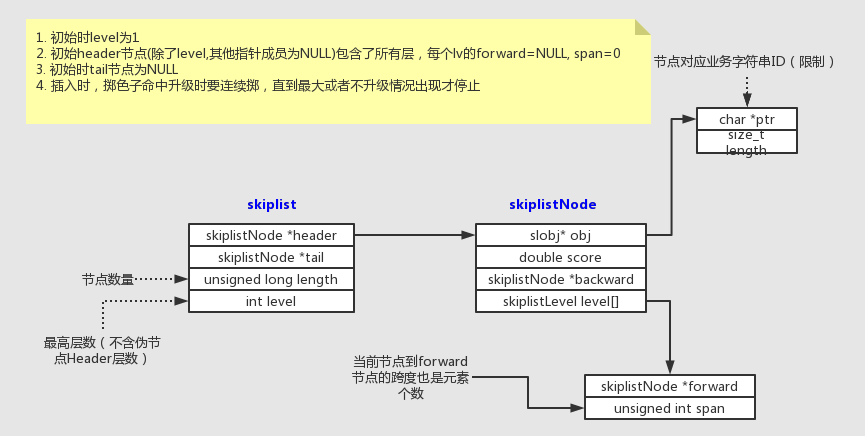
跳表,一种简单的搜索数据结构 跳表是用来快速搜索的数据结构,在大部分情况下可以和平衡树效率相近。他是基于有序双向链表的查找。可以认为是一种兼顾了有序数组快速搜索和链表的随意高效插入两种特性的数据结构。特别是在实现排行榜业务时,基本就是使用他了。而且广为人知的Redis的zset也是跳表的实现。数据结构概览可以看到每个节点有backward指针指向后置节点。Redis中排序是从小到大的。也就是指向比当前节点小的下一个节点。当前节点指向前进方向(变大)节点的指针是有多个的。这也是实现跳进访问,提高有效搜索的关键。在Redis中还有span成员也重要,用来计算搜索到当前节点经过的节点数量,对应的也就是业务中的排名。如果仅用来搜索是不用维护span这个数值的。Redis实现概览出自Redis设计与实现实现关键链表的Header其实是一个伪节点,他从初始化就包含了最大的层数。在Redis下是32层。其他节点的层数是动态的根据幂次定律生成的(掷色子)。查找是从左边顶层往下搜索,遇到小的就进行一次跳跃。否则继续往下层找。直到找到或者到了最小层也无法找到。