搜索到
6
篇与
的结果
-

-
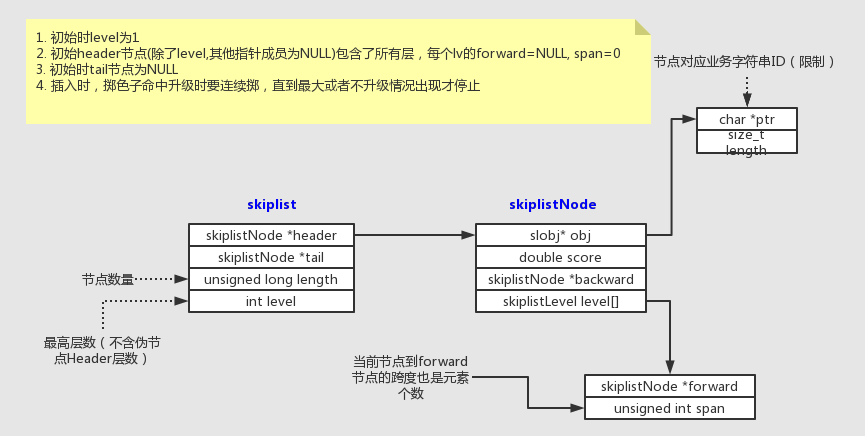
跳表,一种简单的搜索数据结构 跳表是用来快速搜索的数据结构,在大部分情况下可以和平衡树效率相近。他是基于有序双向链表的查找。可以认为是一种兼顾了有序数组快速搜索和链表的随意高效插入两种特性的数据结构。特别是在实现排行榜业务时,基本就是使用他了。而且广为人知的Redis的zset也是跳表的实现。数据结构概览可以看到每个节点有backward指针指向后置节点。Redis中排序是从小到大的。也就是指向比当前节点小的下一个节点。当前节点指向前进方向(变大)节点的指针是有多个的。这也是实现跳进访问,提高有效搜索的关键。在Redis中还有span成员也重要,用来计算搜索到当前节点经过的节点数量,对应的也就是业务中的排名。如果仅用来搜索是不用维护span这个数值的。Redis实现概览出自Redis设计与实现实现关键链表的Header其实是一个伪节点,他从初始化就包含了最大的层数。在Redis下是32层。其他节点的层数是动态的根据幂次定律生成的(掷色子)。查找是从左边顶层往下搜索,遇到小的就进行一次跳跃。否则继续往下层找。直到找到或者到了最小层也无法找到。
-
Redis在游戏的运用(二) 在读多写少的场景,有必要进行热点数据的缓存。缓存可以有效减少DB的读压力。这样的解决方案常见的DB也是具备的。不管是Redis还是MySQL或者是MongoDB, 都有复制集群的概念。只要使用从节点读数据,主节点写数据即可。MongoDB Atlas号称可以秒级别内同步新数据到从节点。这种方案也可以称为主写从读实现读写分离。说完减少主节点压力的优点,缺点也由此引入。这种方案只能实现数据的最终一致性,无法实现强一致性。DB数据的写入一般如下:应用层insert/update/delete返回时只是更新cache和Redo,Undo日志(在Mongodb中是更新oplog),并没有真正写入磁盘。主从binaryLog/Oplog同步延迟。比如机房间网络延迟问题、服务器负载问题等。即使忽略上面同步延迟问题,是不是就没有其他问题了?DB内部的缓存模块对热点数据的定义是死的,他缓存的数据可能不是我们我们认为的热点数据。因为他负责了多个维度数据的读写。比如我只访问了一次的数据,可能因为LRU原因,真正频繁热点数据被置换出缓存。有时我们想自己定义热点数据,比如近期1小时登录的玩家(这里不仅仅包含当前在线玩家)。这里补充扩展下有意思点,MySQL使用了自己改进后的LRU算法,使用了热数据插入队列前进5/8位置。这种优化可以屏蔽全表等大面积遍历引起热点数据的完全失效。于是引进了Redis这类内存DB。在进行写时,如果是需要强一致性。先删除Redis缓存(强迫读请求去DB加载)写入DB(写入会有锁,此时会阻塞读)再删除Redis缓存(即使有读请求在1和2的过程中取到旧数据,这里也会让旧缓存失效)如果需要最终一致性:设置缓存过期时间写入DB总是先尝试更新Redis数据再进行DB更新。如果Redis没有对应数据时可以考虑不进行写入的。因为可能不是热点数据>。另外如果宕机,连接不上也不需要进行更新Redis缓存。在进行读操作时,总是先尝试从Redis中取。如果没有再从DB取。这里要使用布隆过滤防止缓存穿透问题。从DB取数据返回时也写入Redis缓存。这里要注意两个问题:缓存击穿问题:对一个数据有并发多个请求加载。此时要排队加锁。真正进入DB加载时总是先尝试Redis取。更新Redis时缓存雪崩问题。数据过期时间最好进行一个随机,防止某个时间大量数据同时过期而缓存失效。